前提:请先学习爬虫框架BeautifulSoup和Flask中jsonify的简单使用
1、如何使用爬虫框架BeautifulSoup,可以通过慕课网上的课程学习:Python开发简单爬虫
2、使用jsonify将数据转为JSON格式
一、实现简单的爬虫功能
1、选定爬取内容,并对网页代码进行分析
我们以爬取 python中文开发者社区 首页热点文章为例,示意图如下:
网页左侧红框内是要爬取的内容,网页右侧是使用Chrom浏览器查看HTML代码
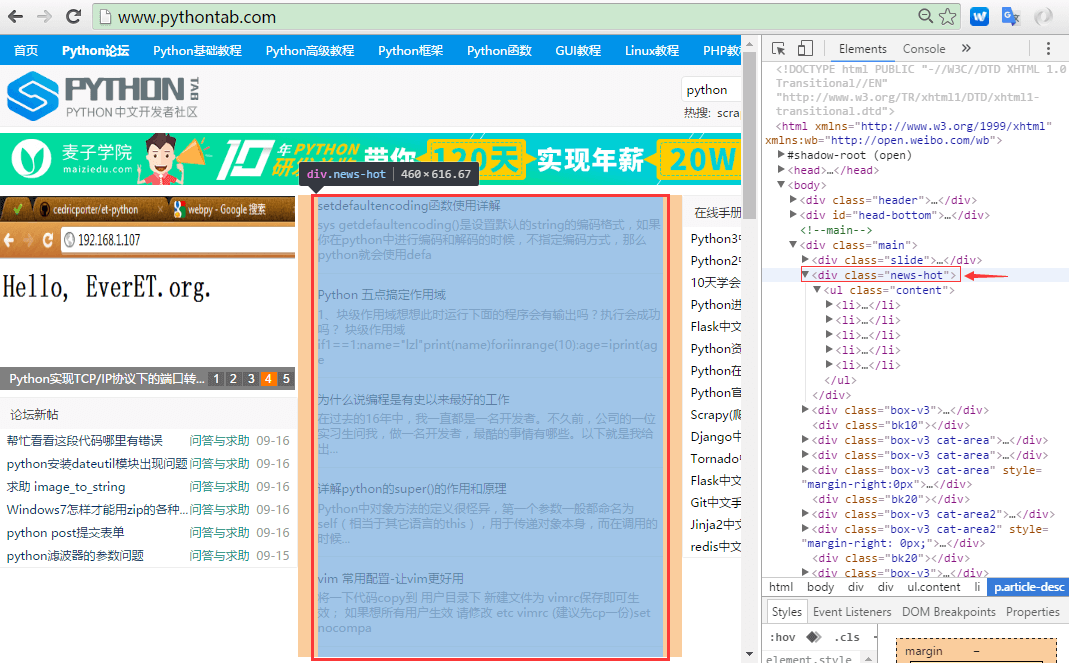
可以看到,我们要爬取的内容是在<div class='news-hot'></div>中,这里我们只爬取目标文章的URL和标题
2、爬虫结构简介
学习过慕课网的视频后,应该对爬虫的结构一定了解,这里用文字归纳一下
一般爬虫的结构主要分为三大部分:爬虫调度器、爬虫、数据输出
其中爬虫又包括三个模块:URL管理器、网页下载器、网页解析器,示意图如下:
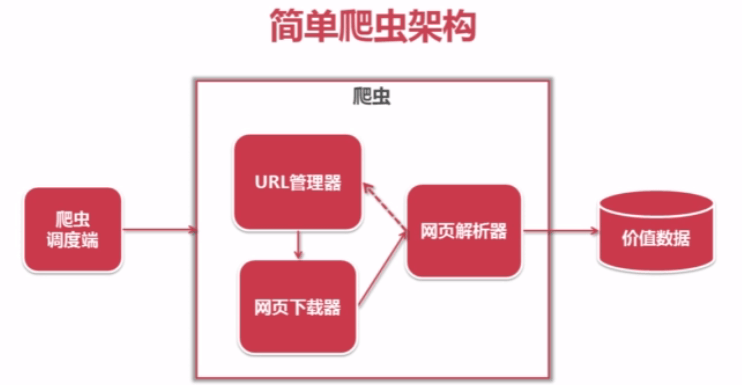
图片取自于CSDN博客,可到作者该博客中深入了解
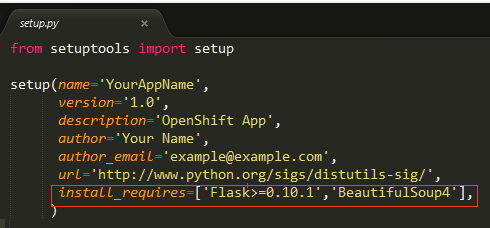
3、添加BeautifulSoup依赖
如何添加第三方依赖库,已在上篇博客中有讲到,添加方法同Flask
4、编写爬虫
因为这里只讲解如何操作及思路,所以下面以最简单的方式来实现
思路:接收外部传入的URL->经过爬虫处理->返回处理后的数据
所有的爬虫操作写在一个文件中(步骤过于简写,也没做异常处理,仅用于理解参考),在保留实现思路的情况下提高易读性
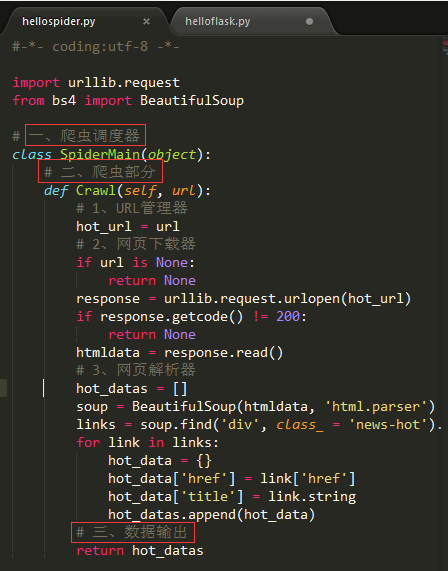
创建爬虫文件hellospider.py,代码如下(截图):
二、将爬取的数据生成在线API
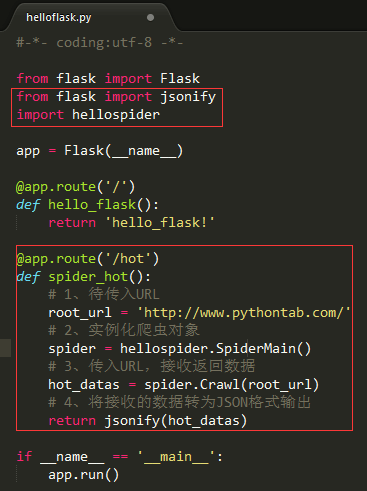
1、在helloflask.py中添加调用爬虫的路径/hot,代码如下(截图):
2、将修改后的应用部署到openshift上
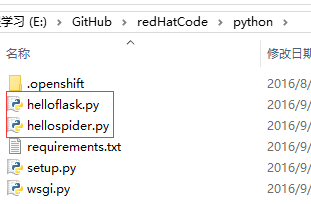
此时,项目目录结构如下:
将本地修改后的项目push到线上
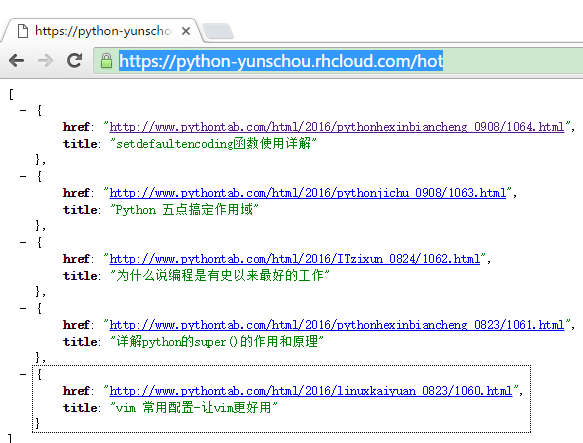
4、访问线上API
终于到了激动人心的时刻,快查看你自己实现的线上API吧
我的线上API访问结果如下:https://python-yunschou.rhcloud.com/hot